AnyAI Lab始動から1ヶ月。杭州でのAI Bootcampで見えた、AI Nativeな事業実装の現在地
Jul 14, 2026
Blog
AnyMind Group


Tech Blog
Influencer Marketing
May 24, 2021
![[Tech Blog] AnyTag/AnyCreatorプロダクト開発の試行錯誤とスケールするチーム作り](https://cdn-contents.anymindgroup.com/corporate/wp-uploads/2021/05/system_structure.png)
こんにちは。AnyMind GroupでEngineering Teamのマネージャーをしている柴田です。 この記事では、当社のAnyTag/AnyCreatorというプロダクトについて、これまでどのような開発体制や技術スタックで開発してきたのかをご紹介しようと思います。
はじめに、このプロダクトがどういったものなのかご説明します。 AnyTag/AnyCreatorは、2つ合わせてインフルエンサーマーケティング全体を支援するプラットフォームとしてアジア各国で展開しています。 インフルエンサーマーケティングでは大きく2種類のユーザーがいると想定していまして、それぞれに適した支援を行うためにプロダクトを分けている形になります。
一つは広告主向けのAnyTagで、自社の製品のプロモーションにふさわしいインフルエンサーのキャスティングやキャンペーンのパフォーマンス管理などを支援します。 最近では、Account Management機能と呼んでいる企業SNSアカウントのグロースや分析を行う機能も展開しています。
もう一つはインフルエンサー向けのAnyCreatorで、ファンの獲得やコンテンツ制作、収益化などの支援を行います。 先日、UUUMさんと業務提携を発表させていただき 、参加してくださっているインフルエンサーさんのデータを分析して、キャンペーンへの活用やD2Cブランドの立ち上げなども支援しています。

さて、プロダクトの紹介はこのくらいにして、パートナー含め広く活用頂いている当プロダクトをどのように開発してきたのかについて、成功失敗を交えてお伝えします。
AnyTag/AnyCreatorは、初期はCastingAsiaという名前でリリースされました。 最初のバージョンでは現Managing Directorの竹本が1人でPHPで開発していましたが、すぐにビジネスの展望が見えたのでエンジニアチームを組成し、開発言語もそこでPythonに置き換わりました。
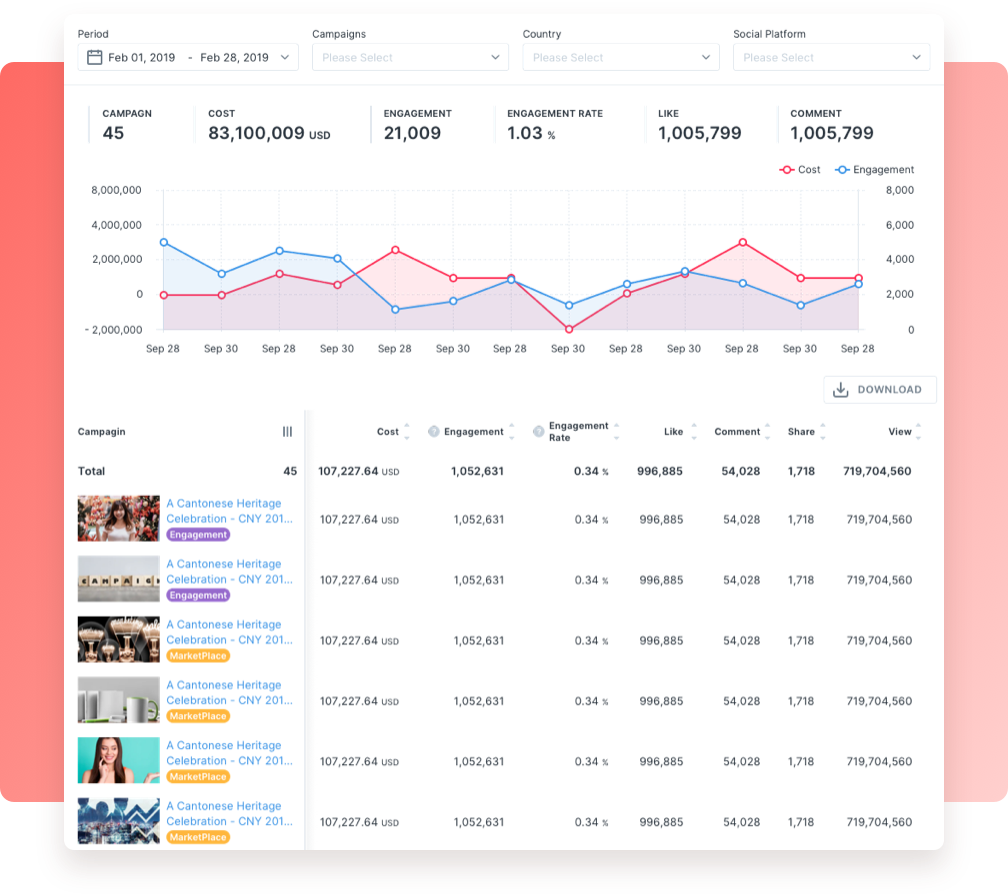
設計としては以下の図のように、RDBの読み書きを担うPostgRESTがいて、ユーザーからのデータ更新やバッチの実行結果によってDBの値が更新され、それをhookに後続のAWS Lambda関数が実行される形でした。

開発チームとしては、コストの最適化と分業しやすさを目指してそれぞれのLambda関数を開発していけばいい形を取っていたのですが、徐々にバグが目立つようになってきてしまいました。 理由は一言で言えばアーキテクトの不在だと思っています。次々に出てくる新機能要望を速度優先で開発するあまり、
といったことが発生し、最終的には「このデータがいつどのLambda関数によって書き換えられたのかわからない」といった有様になっていました。 (ちなみに筆者が過去の資料を探ると240個ほどのLambda関数が見つかりました。それぞれドキュメントが無いため、何をする関数なのかは処理を見る必要があります。)
このような設計が至らない状況かつ、当時のベトナムのエンジニア人材市場の高まりもあって、ほとんどのエンジニアメンバーがチームを離れてしまいました。 ここで、仕方なくプロダクトの作り直しを決断することになります。
筆者が入社したのはちょうどこの時期で、当初は別プロダクトを担当する予定でしたが上記の状況のためこのプロダクトを担当することになりました。 また、ほぼ同じタイミングで優秀なフロントエンドエンジニアの越水が入ってくれたので、彼がフロントエンドを、筆者がバックエンドを、そして前述の竹本がPMという形で作り直しプロジェクトが始まりました。
インフルエンサーマーケティングのビジネスはまだ始まったばかりで、かつ各SNSプラットフォームのアップデートなど変化が激しいため、変化に素早く対応出来るプロダクトであることが求められます。 そこで、『変更に強く品質が高いシステム』、そして『チームをスケールさせられるアーキテクチャ』をゴールに掲げて作り直しを行いました。
設計方針としては、筆者が経験のあったDDD(Domain Driven Design)の方法論を用いて、それぞれのエンティティがどのような振る舞いを担うべきなのか考えながら実装することにしました。 PMの竹本は現行で動いているシステムの開発リーダーだったこともあり、彼の頭にはシステムの全機能やそれぞれどう動くべきかが見えていたので、それをベースにユースケースの洗い出しをし、そこから以下のような図を作成してドメインモデルの設計をしました。 このとき、初めは各種SNSプラットフォームのデータを一元的に管理しようとしていたのですが、プラットフォームごとの違い(アクセストークンの扱い方や、ポストが持つメトリクス)があったので、すぐに分けていく方針に切り替えました。

技術スタックについて、言語は筆者としてはDDDの知見が多いJVM系の言語が良かったのですが、既存コードがPythonで書かれているのでその資産の活用やメンバーの学習コストの観点からPythonを選びました。 当時は既にPythonにも静的型チェックの機能が備わっていて、試している限りドメインロジックの記述は問題ないと判断しました。 結果として、型チェックが効かせられなかったDBアクセス周りはたまにバグを生みましたが、ドメインロジックはキレイに管理出来たと思います。
フロントエンドとのやり取りはGraphQLを採用し、フロントエンド側で欲しいデータを自ら定義してもらってバックエンドがそれに合うようにデータを用意する形を取りました。 これにより、フロントエンドはバックエンドの実装のことを考えずにUIにのみ注力して開発を行うことができ、バックエンドも必要に応じてRead Modelを構築するなど最適化を行いやすくなりました。 当初はRelayも検討したのですが、クライアントがWebフロントエンドのみで汎用的なスキーマは必要なかったので、各ページ向けに特化させたエンドポイントを用意する形を取りました。
これらの改善を経て、DB設計からインフラも全て見直したものを数ヶ月掛けてリリースしました。

ちなみに僕たちが作り直しに注力している間もビジネスは順調で、当然ながら既存システムは多くのキャンペーンを運用する必要がありました。 こちらはベトナムに残っていたエンジニア&サポートの2名が、現行システムが煙を吹いてバグを出す中、踏ん張って保守してくれていました。 また、既存システムのデータを移行する際にどこのデータをどう持ってくれば良いのかもそのエンジニアから教えてもらいました。 彼らなしではここまでスムーズに移行できなかったので、本当に助かりました。
なんとかバグだらけのシステムを作り変えたので、次は攻めです。 ずっと積んでいた追加機能の要望を開発速度を上げて対応するため、エンジニアを増やしてスケールする体制を作る必要がありました。
フロントエンドについては、初期から熱望されていたインフルエンサー向け機能のモバイル版のリリースが主でした。 WebフロントエンドではReactを採用していたのでExpoを選び、ドメインロジックはバックエンドに集約していたこともあって、ほとんどWebの知識を流用して実装することが出来ました。 Webと大きく異なるところは、UIコンポーネント以外で言うとSNSログインでネイティブの画面遷移を使うことくらいだったと記憶しています。
一方でバックエンドは、チームを分割したい、DDDをより推進していきたいとの思いからマイクロサービス化を行いました。 DDDを取り入れやすい言語(筆者の観測範囲では、Pythonで静的型チェック・DDDを取り入れているチームは少ない)、外部APIを叩くことが多いため非同期処理を扱いやすい言語が好ましい、という理由から、分けたサービスではKotlinを採用し、Java経験のあるメンバーを採用していきました。
マイクロサービス化に合わせて、GraphQLのProxy (Apollo Federation) の導入を行ったり、インフラ面でも様々なサブシステムの展開しやすさ・コストの圧縮のためにGKEを採用したり、デプロイ基盤なども整えていきました。
(以上、それぞれ工夫した点はもっとあるのですが、長くなってしまうので別の記事でご紹介したいと思います。)
チームメンバーが10人を超えてきて、サブシステムによって技術スタックや必要なドメイン知識が異なるということから、いよいよ2チーム体制に舵を切り始めます。大きく
という形でバックエンドチームを分割し、独立してスクラムミーティングを行い開発出来るようにしました。 一方で、ややこしいのですがフロントエンドは1チームのままにしていて、変則的ですが両方のバックエンドチームのミーティングに入ってもらう形を取っています。 というのも、AnyTag/AnyCreatorが機能の分割がフロントエンドとバックエンドで異なるためです。
上記で触れたキャンペーン管理機能を例に取ると、広告主向けにはキャンペーンに誰が参加したかや予算消化率が見れるようにしますが、同時にインフルエンサー向けには対象のキャンペーンへの参加や収益の管理を行う必要があります。 一つの機能が2つのフロントエンドで使われ、当然ながらどちらかが欠けても機能として意味を成さないため、チームの分け方はバックエンド中心にして、フロントエンドは両方ともサポートしてもらうようになりました。 これはフロントエンドは主に画面の表示ロジックだけに注力できるようにGraphQL Schemaに定義するようにしていて、ドメイン知識の要求度合いがバックエンドよりも薄いことも理由としてあります。

ちなみにこの頃には筆者もマネージャーとして組織全体を見るようになったため、チームのTechLeadを別の方に譲り、週一回の全体での方向性の議論にのみ顔を出すようになりました。
以上がAnyTag/AnyCreatorプロダクト開発のチーム組成です。 この半年ほどは新しいTech Leadの方が事業ドメインに詳しくなってくれていて、システム構成も彼らが考えてサブシステムの追加やシステム間のメッセージでのやりとりなど手を加えてくれています。
AnyTag/AnyCreatorは、繰り返しになりますが外部SNSプラットフォームに依存している性質上、彼らのアップデートに対応し続けるため永遠に安定しないシステムであると言えます。 そのため、いつ仕様が変わっても対応できるように「ここを変更したらどこに影響するのか」「なぜ今このような設計にしているのか」を全員が把握できるコードベース・ドキュメントを目指しています。
その際に、マイクロサービスとして切り出していくことは責務の明確化とチームのスケール両面で役に立つと考えていまして、幸いにもここまでは順調に来れています。 ここから、さらにメンバーを増やしてより開発スピードを上げていけるように取り組んでいきます。
—
AnyMindでは、AnyTag/AnyCreatorをはじめ様々なプロダクトを開発しており、PdM、エンジニアの採用も強化しています。ご興味がある方はこちらのページから「Product Development」を選択して募集職種をご覧ください。
https://anymindgroup.com/career/
また、こちらはAnyMindのエンジニア達が書いているブログです。よろしければこちらもご覧ください。